GarVerseLOD: High-Fidelity 3D Garment Reconstruction from a Single In-the-Wild Image using a Dataset with Levels of Details
1. SSE, CUHKSZ 2. FNii, CUHKSZ 3. Huawei Noah’s Ark Lab 4. DCC Algorithm Research Center, Tencent Games

We propose a hierarchical framework to recover different levels of garment details by leveraging the garment shape and deformation priors from the GarVerseLOD dataset. Given a single clothed human image searched from Internet, our approach is capable of generating high-fidelity 3D standalone garment meshes that exhibit realistic deformation and are well-aligned with the input image.
Abstract
Neural implicit functions have brought impressive advances to the state-of-the-art of clothed human digitization from multiple or even single images. However, despite the progress, current arts still have difficulty generalizing to unseen images with complex cloth deformation and body poses. In this work, we present GarVerseLOD, a new dataset and framework that paves the way to achieving unprecedented robustness in high-fidelity 3D garment reconstruction from a single unconstrained image. Inspired by the recent success of large generative models, we believe that one key to addressing the generalization challenge lies in the quantity and quality of 3D garment data. Towards this end, GarVerseLOD collects 6000 high-quality cloth models with fine-grained geometry details manually created by professional artists. In addition to the scale of training data, we observe that having disentangled granularities of geometry can play an important role in boosting the generalization capability and inference accuracy of the learned model. We hence craft GarVerseLOD as a hierarchical dataset with levels of details (LOD), spanning from detail-free stylized shape to pose-blended garment with pixel-aligned details. This allows us to make this highly under-constrained problem tractable by factorizing the inference into easier tasks, each narrowed down with smaller searching space. To ensure GarVerseLOD can generalize well to in-the-wild images, we propose a novel labeling paradigm based on conditional diffusion models to generate extensive paired images for each garment model with high photorealism. We evaluate our method on a massive amount of in-the-wild images. Experimental results demonstrate that GarVerseLOD can generate standalone garment pieces with significantly better quality than prior approaches while being robust against a large variation of pose, illumination, occlusion, and deformation.
Overview
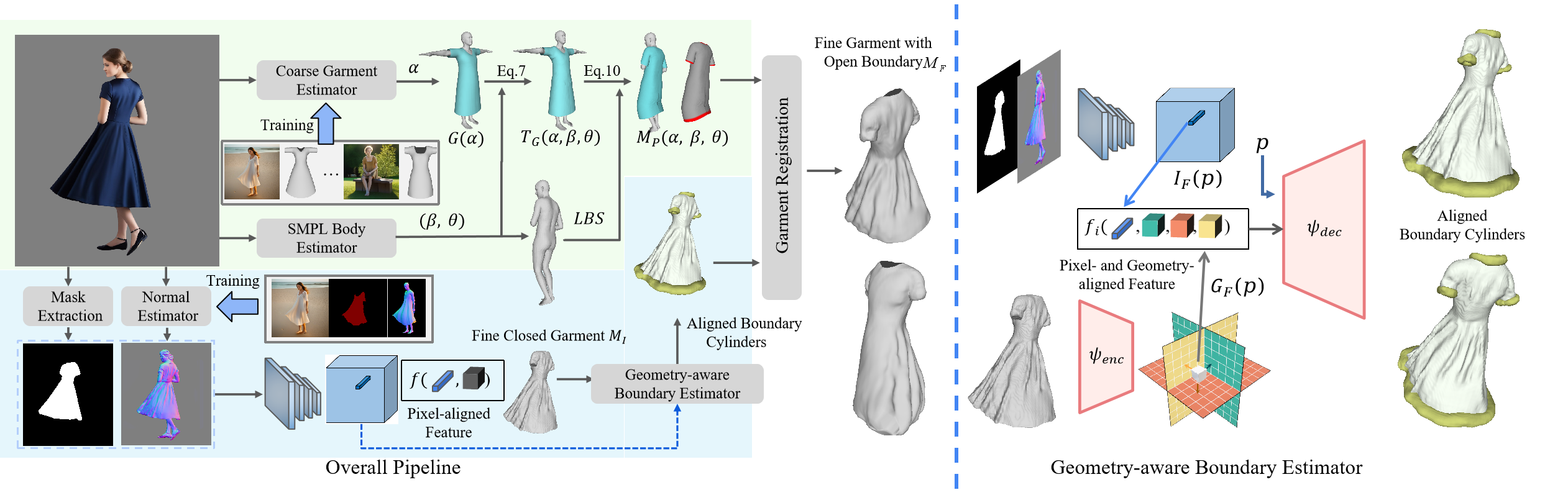
The pipeline of our proposed method. Given an RGB image, our method first estimates the T-pose garment shape and computes its pose-related deformation with the help of the predicted SMPL body. Then a pixel-aligned network is used to reconstruct implicit fine garment and the geometry-aware boundary estimator is adopted to predict the garment boundary. Finally, we perform garment registration to obtain the final mesh, which is topologically consistent and has open boundaries.
More Results on Loose-fitting Garments




Reference
@article{luo2024garverselod,
title={GarVerseLOD: High-Fidelity 3D Garment Reconstruction from a Single In-the-Wild Image using a Dataset with Levels of Details},
author={Luo, Zhongjin and Liu, Haolin and Li, Chenghong and Du, Wanghao and Jin, Zirong and Sun, Wanhu and Nie, Yinyu and Chen, Weikai and Han, Xiaoguang},
journal={ACM Transactions on Graphics (TOG)},
year={2024}
}